What is Casper?
Although one-sided communication semantics can asynchronously handle communication progress, the MPI standard does not guarantee it to be truly asynchronous. In most network interfaces, complex one-sided communication operations such as noncontiguous accumulate are not natively supported. MPI implementations still require the target process to make MPI calls in order to ensure completion of such operations.
Casper is a process-based asynchronous progress model for MPI RMA communication on multicore and many-core architectures. The central idea of Casper is to keep aside a small, user-specified number of cores on a multicore or many-core environment as “ghost processes,” which are dedicated to help asynchronous progress for user processes through appropriate memory mapping from those user processes.
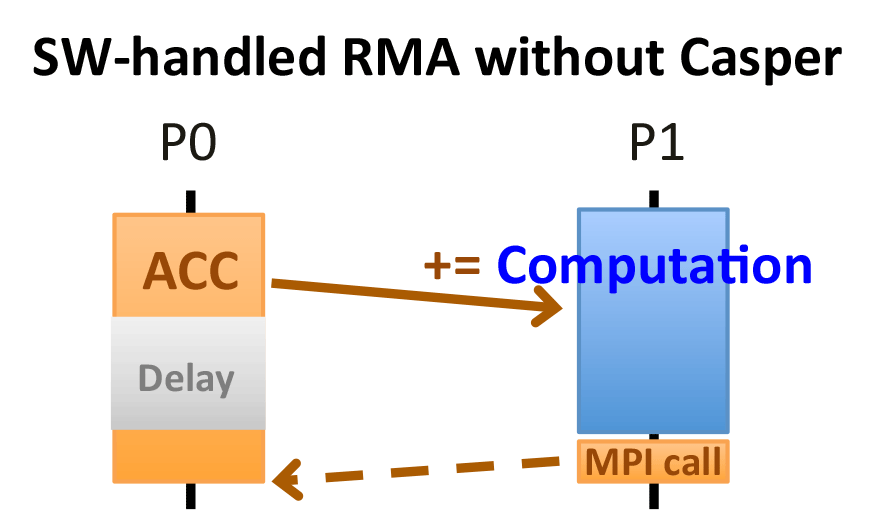
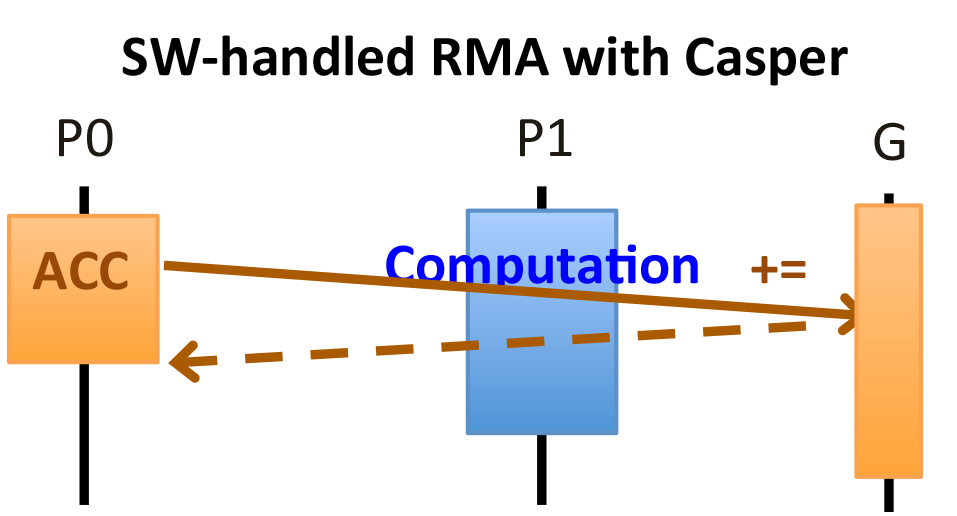
Why Casper?
Flexible
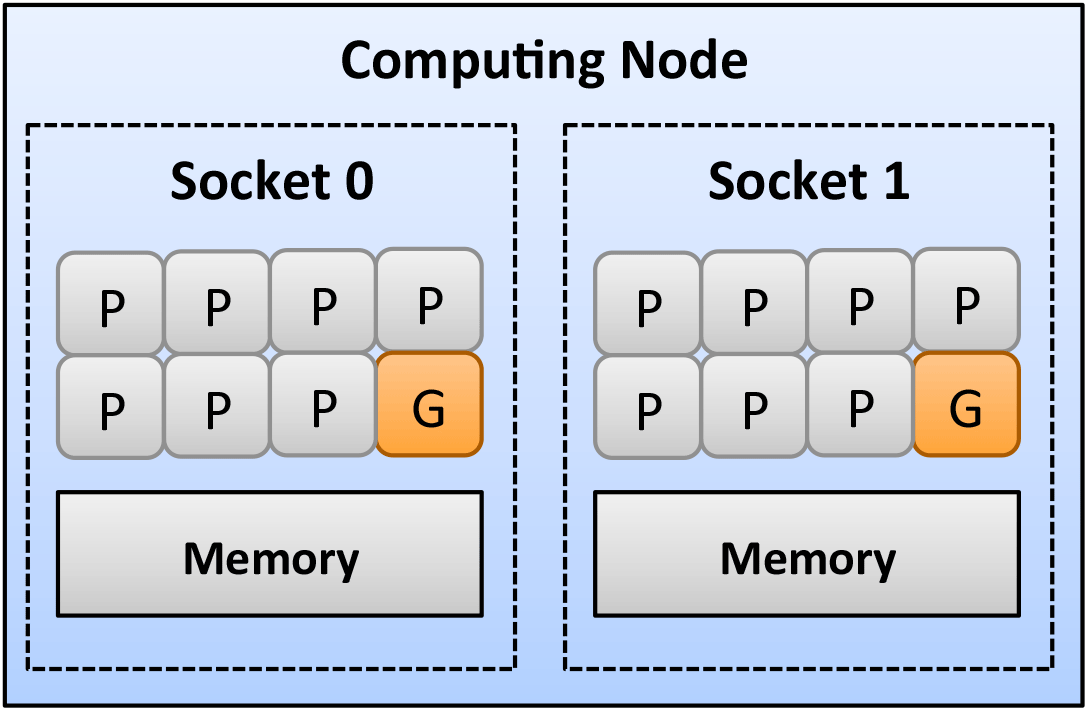
Casper is centered on the notion that since more and more cores are embedded into computing systems, some of these cores may not always be busy performing computation, and hence it may be more efficient to dedicate some of them to perform progress on asynchronous communication.
Casper allows user to dedicate arbitrary number of cores to asynchronous progress. This figure shows an example of a topology-aware core deployment in Casper, including user processes (P) and “ghost processes” (G).
Portable
Casper is designed as an external library through the PMPI name-shifted profiling interface of MPI, which allows Casper to transparently link with any MPI implementation on various platforms.
Performance Showcase
Asynchronous Progress Microbenchmark
In order to simulate the typical computation-communication pattern in RMA applications, every process communicates with all the other processes in a communication-computation-communication pattern. We use one RMA operation (size of a double) in the first communication, 100 microseconds of computation, and ten RMA operations (each size double) in the second communication. Full sample code is available here.
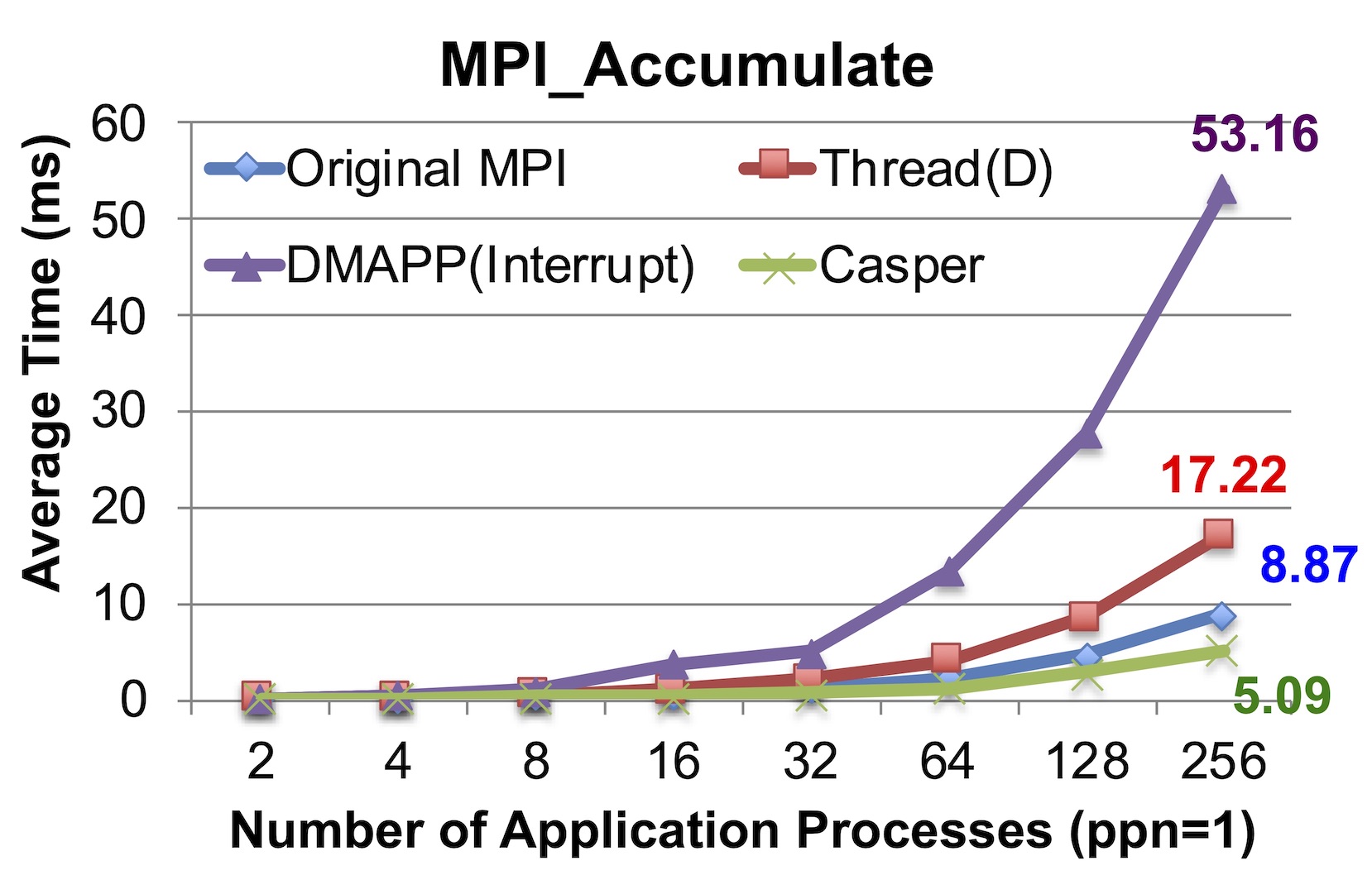
We measured it on a Cray XC30 supercomputer (NERSC Edison), and used one process per node and scale the number of nodes for both Accumulate and Put.
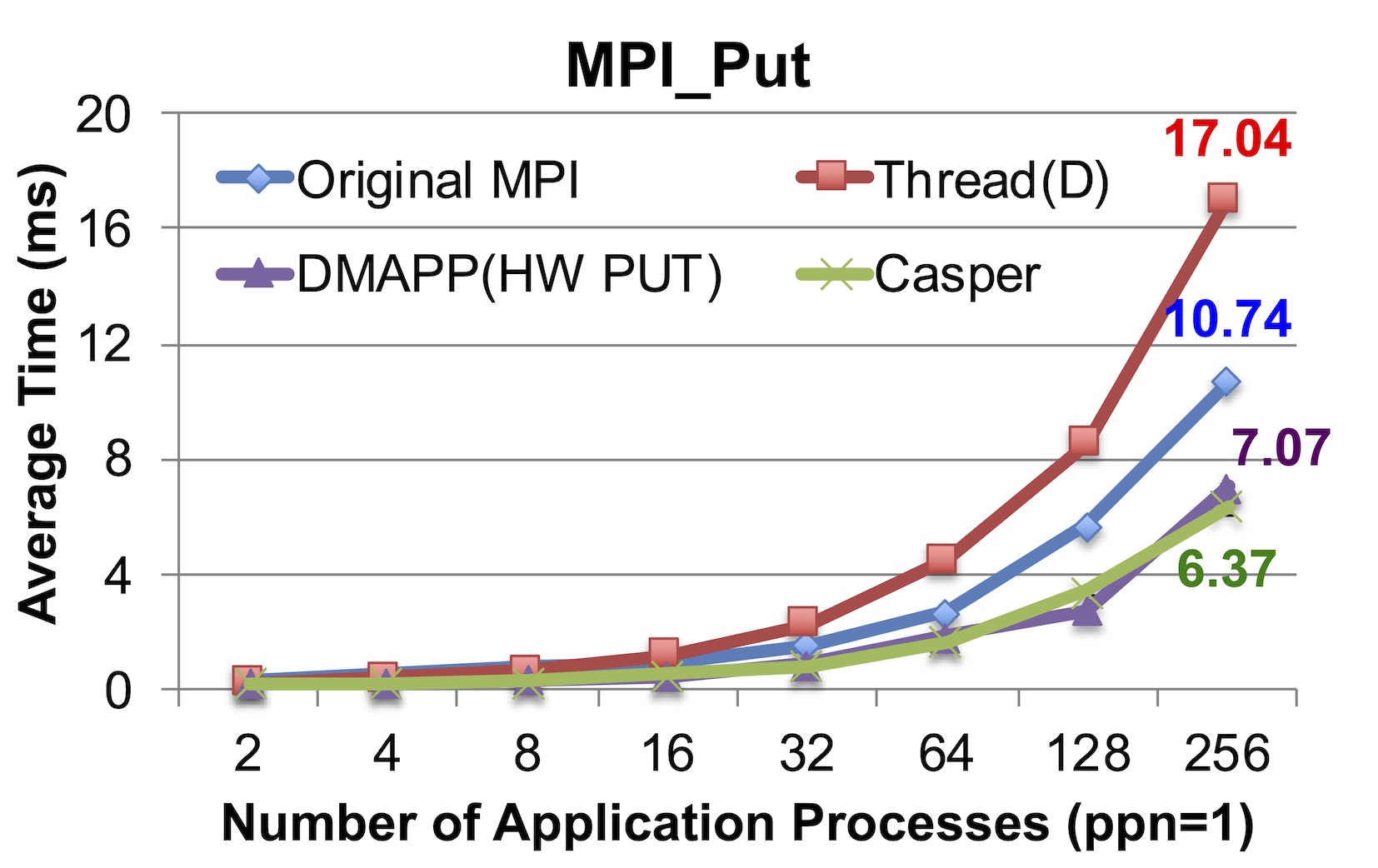
Accumulate is handled by software in Cray MPI. Comparing with traditional thread-based or interrupt-based asynchronous progress approaches, Casper provides more efficient asynchronous progress for software-handled RMA operations.
Put is handled by software in Cray MPI default mode, but by hardware in the DMAPP mode. Casper does not affect the performance of hardware-handled operations.
NWChem Quantum Chemistry Application
NWChem is one of the most widely used computational chemistry application suites. It is developed based on the Global Arrays toolkit because of the large memory needs that require memory sharing across multiple nodes. This experiment used ARMCI-MPI as the portable implementation of Global Arrays, which internally performs MPI RMA communication.
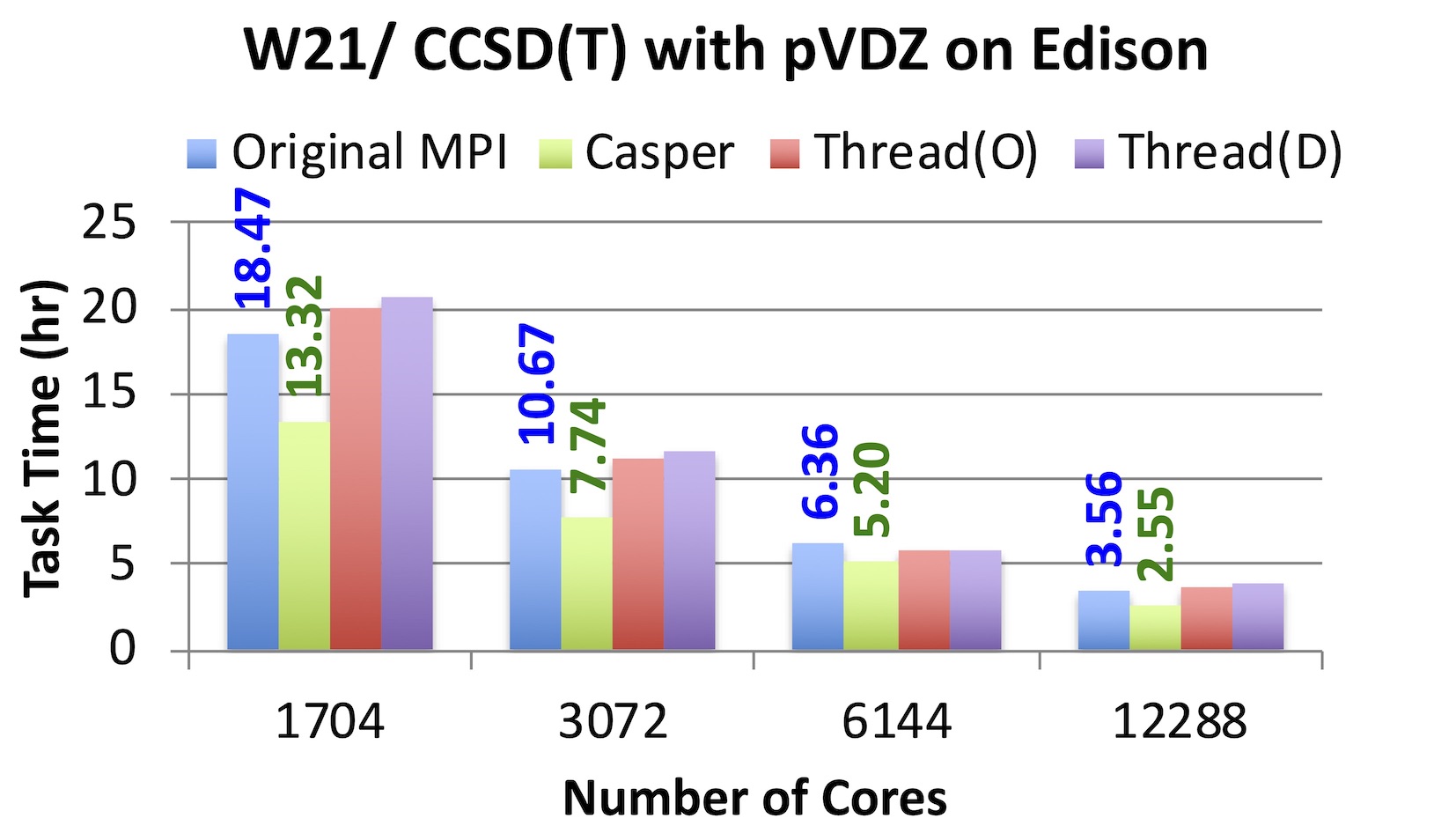
In the “gold standard” CCSD(T) simulation for a very large water problem W21 with pVDZ, Casper always shows consistent improvement with increasing number of cores.